
Flag #24 - Unpacking Stable Diffusion
As an avid Japanese animation fan, I had an interesting question in my mind back then: How can the machine identify anime characters? If you missed it, I wrote a few blog posts to explain my journey.
In 2017, I tried playing around with TensorFlow and learned classical MNIST dataset to classify handwritten digits between 0-9. On the same year, I tried building a transfer learning model for identifying anime character images. I realized feature extractions for anime images were quite tricky as I couldn't simply apply human face recognition model without modification.
In 2019, there's a boom of interests in interpretability for machine learning models, such as LIME and SHAP. I learned that my model tried to recognize anime characters mainly from their hair.
Fast-forward to 2022, we are back to sudden AI advancements: GPT-related model (ChatGPT) and particularly, stable diffusion in image processing. Why is stable diffusion gained popularity? I decided to take a quick look into the black box and summarized them here!
Stable Diffusion
Stable diffusion is released in 2022 by a collaboration between Stability AI, CompVis LMU, and Runway with support from EleutherAI and LAION. It brings several capabilities, ranging from generating image from text description, inpainting & outpainting, and so on.
It was trained with LAION-5B dataset, which contains 5.8 billion of image & text pairs data. To give a bit more picture, this dataset is 10 times bigger than LAION-400M released in 2021 and much bigger than Google Dataset (Open Images V7) containing 10M images. As you can imagine, this LAION-5B dataset is very enormous, 384 px of them equals to 240 TB of storage!
Image from https://laion.ai/blog/laion-5b/
Taking a look into the paper "High-resolution image synthesis with latent diffusion models", it explained stable diffusion in details with the following architecture.
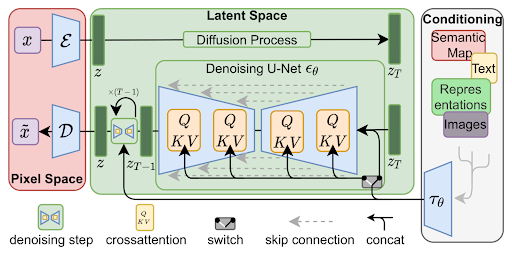
Stable diffusion architecture
Let's take a brief look into each terminologies on the architecture above.
Difussion Process
In the training process, we are trying to add Gaussian noise to make the images blurry.

Add noise to training dataset
Afterwards, we will train our model to predict the noise and subtract it from the input. On each denoising steps, we we will get an image which is closer to the original image (noise = 0).

Stable diffusion: Behind the screen
I recommend reading this blog post by Jay if you're interested in knowing more details about stable diffusion.
Pixel Space -> Latent Space
From the architecture above, you can see an interesting transformation from pixel space to latent space. This technique is also the strength of stable diffusion where it tries to improve the performance by compressing pixel space to latent space. This allows stable diffusion to run 10x faster than the traditional learning in pixel space.
One of the clear drawback is the loss in fine-grained pixel accuracy. However, the research paper claimed that this loss is insignificant compared to the performance benefits that it gets.
For the reference, stable diffusion model takes 150k GPU hours and costs 600 000 USD. One can imagine the $$$ needed if it runs 10x slower!
There's a famous proverb, "With a great ~~power~~ electricity bill comes a great ~~electricity bill~~ power".
Attention Layer
One of the component in the architecture diagram above is cross-attention. This is where stable diffusion gets its text-to-image capabilities.
Attention layer in machine learning is popularized around 2017 by a team from Google OpenAI. It basically tries to mimic human's cognitive attention. Attention layer is also used in GPT models!
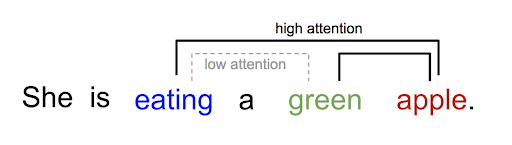
Low vs high attention
In the sentence above, "eating" has a strong correlation with "apple" and "green" has a strong correlation with "apple", but "eating" & "green" doesn't really make sense if it's standalone.
Before attention layer is popularized, this is usually implemented with a fixed-length context vector, such as LSTM or GRU. However, this doesn't really work for long sentences since it's a single context vector. The solution? Attention layer builds multi-layered vectors!

Visualizing attention layer weights by https://dennybritz.com/posts/wildml/attention-and-memory-in-deep-learning-and-nlp/
In the image above, you can see the correlation between each words in a text with an image. This also serves as its interpretability, where we can see which part of the image is being described by each words.
The benefit of attention layer is clear, but the drawback is also clear. As it needs to build a multi-layered vectors, it also requires a huge computational costs. If you're interested in learning attention layers, I recommend you to read the following article.
Classifier-free Guidance
This is not clearly written in the architecture above, but a classifier-free guidance serves as a missing puzzle piece of the stable diffusion learning process. Without a guidance, we mostly ended up with a very flexible, blurry image during the de-noising process.

Non-guided vs classifier-free guided samples
The idea behind a classifier-free guidance is to provide a guidance without building a new classifier. We jointly train a conditional and an unconditional models simply by randomly removing some identifiers from the conditional model.
Waifu ... Diffusion?
Fortunately, someone else on the internet has built a waifu diffusion model so that I don't need to build it by myself. Waifu diffusion is a fine-tuned model based on stable diffusion, trained with 680k text-image samples from booru sites. The creator mentioned it took 10 days with a total cost of 3100 USD to train the model (8 x 48 GB GPUs, 24 vCPU cores, 192 GB RAM, 250 GB storage).
As shown in the creator's page, the waifu diffusion model can generate the following image by supplying the following text: "masterpiece, best quality, 1girl, green hair, sweater, looking at viewer, upper body, beanie, outdoors, watercolor, night, turtleneck".

A sample of image generated by waifu diffusion
Challenges
One of the most obvious challenge is the expensive nature of building a stable diffusion-like models. The original model itself costs hundred thousand dollars and a fine-grained derivative models such as waifu diffusion can easily cost thousand dollars.
Since the model learns from images distributed on the internet, there are a lot of debates about copyright issues. There are also techniques applied by bad actors which can mimic a targeted person art style. In addition, due to enormous size of training dataset, it's hard to filter out sensitive data.
On the technical level, stable diffusion has limited diversity due to the usage of classifier-free guidance in the training. It's also trained in a latent space, which causes loss in fine-grained pixel details. Initially, the model is trained to mainly support 512 px images, but later it's upgraded to 768 px images.
OpenAI: Consistency Models
As mentioned above, diffusion model is still pretty slow and expensive. Diffusion models depend on an iterative generation process that causes slow sampling speed and caps their potential for real-time applications.
In order to find a workaround for this issue, OpenAI published another paper titled "Consistency Models" a few months ago. This model is proposed to support one-step image generation by design (speed vs compute quality). If you're interested, please take a look into the paper!
GLAZE: Protection Against Style Mimicry Attack
The advancement of technology always brings the race between good and bad actors. With the sudden advancement of AI, bad actors try to misuse stable diffusion for mimicking famous artists artstyle.
Researchers from University of Chicago introduced GLAZE, a system introduced to protect human artists by disrupting style mimicry. By adding 5% perturbation to the original artwork, it can give ~95% protection against style mimicry attack. The researchers asked various artists about their opinion on GLAZE and over 90% artists mentioned they are willing to reduce the quality of their image (with perturbation) in order to protect their style from getting stolen.

GLAZE in action
Conclusion
Stable diffusion has brought us an endless possibilities on what we can do with AI & image processing. Adobe integrated AI features to its Photoshop, Google integrated AI features to its Pixel phones for photo enhancement, and so on. A few other ideas that I can think of:
- Designer can create a mockup generated from text and polish the result
- Illustrator can create a rough lines and ask AI to complete the illustrations
- Game developers can utilize AI to improve CGI quality
- Marketers can create ads mockup from text
- Medical members can utilize AI to have a better assistance in identifying disease from rontgen images
- Self-driving cars can utilize AI to improve its accuracy
- And so on
While stable diffusion has been mostly eclipsed by the booming popularity of ChatGPT, I believe both technologies can be integrated with each other for a better, improved performance. To begin with, both of them are utilizing attention layers to a certain extent behind the screen. If researchers find a way to improve ChatGPT, it will also offer a similar potential improvement to stable diffusion and vice versa.
Thanks for reading and see you next time!
--
Iskandar Setiadi
Freedomofkeima's Github