
Flag #14 - A Journey of Improving System Performance
Hi there! It's a while since the last time I wrote something here. In the past few months, it's been an exciting time where there are a lot of performance tuning happening around here. And there you go, I will talk several stuffs related to it this time. It will not be that technical, "top-secret" information, you know :)
"Make it work, make it right, make it fast" -- the quote, which is coined by Kent Beck, is so popular that perhaps almost all software engineers must have ever heard about it. When a feature is developed, programmers always start writing code to satisfy the most generic cases first. From there onward, tests are added to check whether the code can handle boundaries cases or not. The last part, "make it fast", is the most interesting point to explore since there are a lot of aspects that can be improved from it.
From the system perspective, we can monitor how efficient a system is from the running time of a code, the number of resources (CPU usage, memory usage), or even the size of the code itself. From the user-level perspective, we need to consider whether the user is satisfied with the speed, usability, and many other non-functional aspects of a system. From the business-level perspective, we need to consider how much money is needed to serve X number of users and how performant our system is compared to our competitors. And finally, from the developer perspective, we need to consider the maintainability and readability of the codebase. "Make it fast" means a continuous improvement and it is an integral aspect in software engineering.
Database is your friend
Have you ever wondered why your website or background worker feels slow while it should not do any expensive operations? Or have you ever wondered why your database / cache throughput is high while the number of user requests should not generate such an enormous amount of traffic?
200 GET /login/ takes x years
Ran million number of queries for this request

In case you haven't watched it, there's a very good talk about "wat": https://www.destroyallsoftware.com/talks/wat
Digging more into the problem, we tried to debug all database queries from handlers which are often accessed by the users. We found out the underlying problem is very simple, a DB record is unintentionally retrieved same record several times from the DB layer while the data can be reused. This problem often happens when a handler needs to execute different functions which are written by different people.

After fixing redundant DB queries by determining whether we need to retrieve them and retrieve it before running each independent modules, we are finally able to reduce unnecessary queries by 40% and reduce number of servers by 20% while improving the overall system performance.
Infrastructure is your friend
Nowadays, a lot of cloud applications are hosted at the top of Amazon Web Services (AWS), Microsoft Azure, or Google Cloud Platform (GCP). Then, you need to start thinking of your development stack. For example, do you prefer to use a SQL database (AWS RDS / Azure SQL / Google Cloud SQL) or NoSQL (DynamoDB / Cosmos DB / BigTable)? Depending on your use case, choosing a wrong stack might cause more trouble in maintaining the entire infrastructure than writing the actual functioning code.
In the current case, we are utilizing Docker + ECS for deploying our application cluster. Earlier last year, AWS introduced a new kind of load balancer: Application Load Balancer (ALB) which runs at Layer 7. The most exciting feature from ALB for us is native support for container-based application (ECS). Traditionally with ELB, dynamic port mapping is difficult to handle since a docker container is usually configured to run at a certain port and ELB will handle the rest (health check, etc). The problem is when you want to run multiple containers with a single task definition in a single instance.
Going further back to the past, we tried utilizing multi-process feature from our language framework, which is basically creating a fork of child processes. However, Docker is not a fan of fork (a very good explanation by Graham Dumpleton here). We still tried setting multi-process value to "2" and we encountered a random error, 1 out of 50 containers or so, which caused "504 Gateway Error" and the container was simply stuck on the boot-up process. The other idea was to use internal nginx for multi-container routing, but the health check would be weaker and we didn't want to compromise that. This enforced us to scale out instead of scale up in term number of servers.
another "wat" moment
The shiny new ALB allows us to solve the problem described above. By specifying host port value to "0", then the host port is dynamically chosen from the ephemeral port range of the container instance (32768 - 61000).
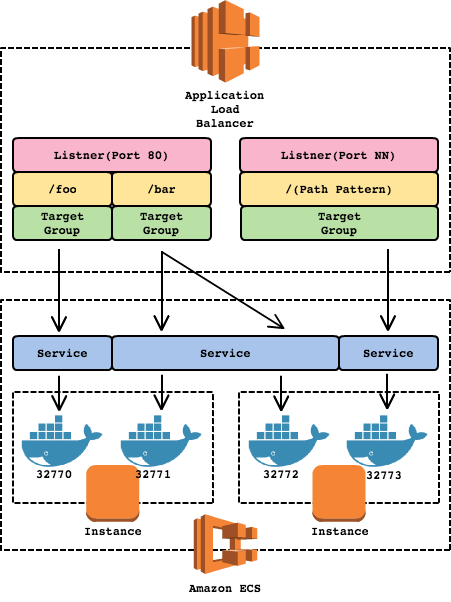
Image reference: http://crmtrilogix.com/images/uploaded/ELB%20Docker%20ECS.png
{kind=link}
Before migrating to ALB, we need to consider several things, such as the differences in log format, new IAM role :duh:, and Layer 7-only supports. Overall, migrating ELB to ALB allows us to scale up in addition to scale out, which reduces number of running instances significantly (by upgrading them to larger instance types) and it makes monitoring a lot easier and cheaper. Performance-wise, it increases overall performance by 5-10% since requests will be more balanced across instances and more-active container will be able to use resources from less-active container on the same instance.
Programming language is your friend
Programming language war, also known as "The Great Programmers War", has occurred for decades and the bloodshed is definitely brutal. On that note, I will not say language A is always better than language B or vice versa here.

Python 2 and Python 3 have a lot of wars and arguments going on right now. Python 2 has more supported libraries and if you are doing a lot of calculation with simple integers, the overall performance might be better than Python 3 since Python 3 "int" behaves similar to the "long" type in Python 2. However, Python 3 has a better support for asynchronous programming (asyncio) for I/O bound operations, optional static typing, and Python 2 will be no longer maintained after 2020. If you have ever used Twisted in Python 2, asyncio should not be a new things for you.

Image reference: https://cdn-images-1.medium.com/max/1600/1*XZlkILfsMj8nOnnXj5bnqw.png
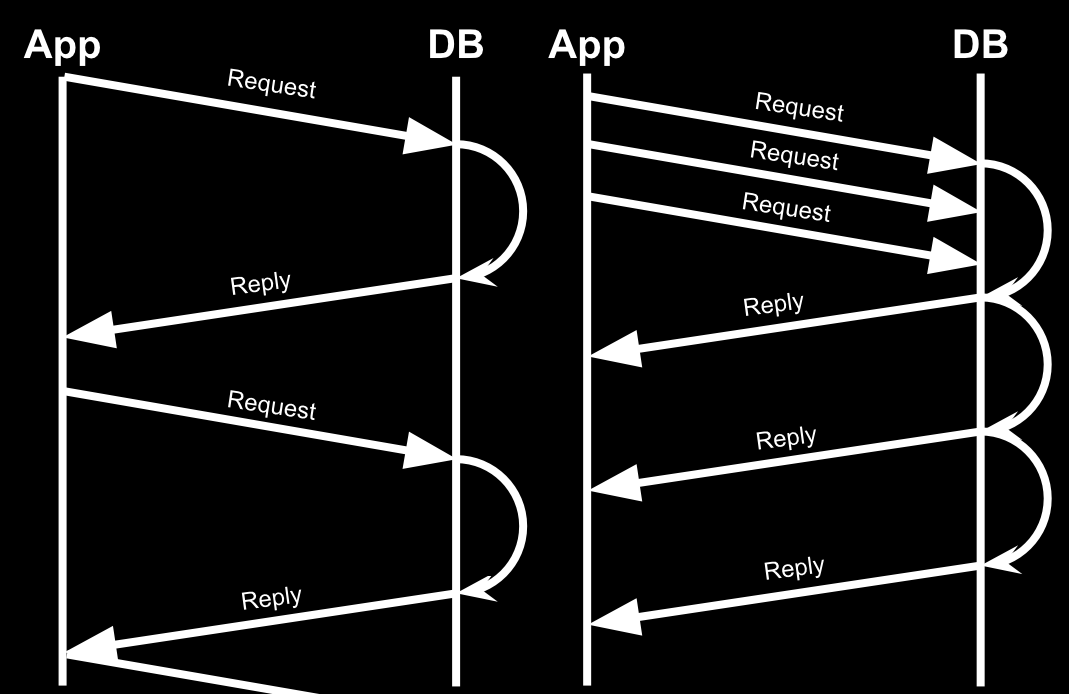{kind=link}
Asyncio is a very exciting stuff for web-related development since a lot of things are I/O bounds (e.g.: DB queries) rather than CPU bounds (e.g.: in machine learning). Quoted from a Hacker Noon post about asyncio by Nick Humrich, it describes why asyncio is better than multi-threading:
Threads come with issues such as resource starvation, dead-locks, and race conditions. It also creates context switching overhead for the CPU.
A talk about Python 3 and asyncio needs an entire lengthy new post, so I will not go into details here. If you are interested in the details, please check the following video by a fellow teammate!
A talk by Jonas Obrist in Euro Python 2017 about "Why you might want to go async"
As a result of Python 2 to 3 migration and around 20% changes to asyncio at the critical section of codebase, we are able to reduce average response time by 30% (from 350ms to 250ms) and number of servers by another 25%.
Overall, the whole performance tuning takes less than half a year while we are still developing on actual functional milestones. It also makes the system twice better in various metrics: average response time, number of servers, and so on!
There are a lot of inspiring stories out there about system improvement and cost reduction:
- Instagram Python 2 to 3: Python 2 to Python 3 upgrade by one of the largest Python user in the world
- AWS Cost Optimization: Optimize infrastructure cost, specifically on Amazon Web Services
- Serverless is cheaper, not simpler: Don't over-optimize your system in the wrong direction, learn the correct use cases & benefits first
Hopefully, this post will be helpful for you. See ya!
--
Iskandar Setiadi
Software Engineer at HDE, Inc.
Freedomofkeima's Github